Radiomics-Guided Global-Local Transformer for Weakly Supervised Pathology Localization in Chest X-Rays
Abstract
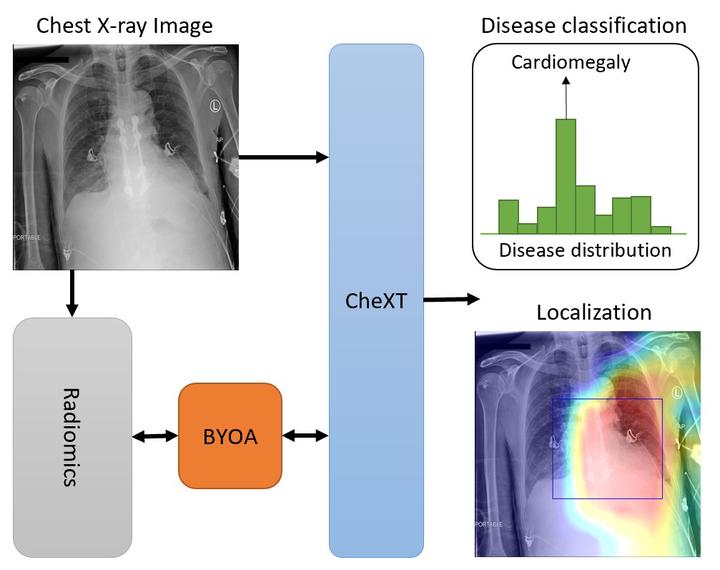
Before the recent success of deep learning methods for automated medical image analysis, practitioners used handcrafted radiomic features to quantitatively describe local patches of medical images. However, extracting discriminative radiomic features relies on accurate pathology localization, which is difficult to acquire in real-world settings. Despite advances in disease classification and localization from chest X-rays, many approaches fail to incorporate clinically-informed domain knowledge. For these reasons, we propose a Radiomics-Guided Transformer (RGT) that fuses global image information with local knowledge-guided radiomics information to provide accurate cardiopulmonary pathology localization and classification without any bounding box annotations. RGT consists of an image Transformer branch, a radiomics Transformer branch, and fusion layers that aggregate image and radiomic information. Using the learned self-attention of its image branch, RGT extracts a bounding box for which to compute radiomic features, which are further processed by the radiomics branch; learned image and radiomic features are then fused and mutually interact via cross-attention layers. Thus, RGT utilizes a novel end-to-end feedback loop that can bootstrap accurate pathology localization only using image-level disease labels. Experiments on the NIH ChestXRay dataset demonstrate that RGT outperforms prior works in weakly supervised disease localization (by an average margin of 3.6% over various intersection-over-union thresholds) and classification (by 1.1% in average area under the receiver operating characteristic curve). We publicly release our codes and pre-trained models at https://github.com/VITA-Group/chext.