Efficient deep learning-based automated diagnosis from echocardiography with contrastive self-supervised learning
Abstract
Background: Advances in self-supervised learning (SSL) have enabled state-of-the-art automated medical image diagnosis from small, labeled datasets. This label efficiency is often desirable, given the difficulty of obtaining expert labels for medical image recognition tasks. However, most efforts toward SSL in medical imaging are not adapted to video-based modalities, such as echocardiography.
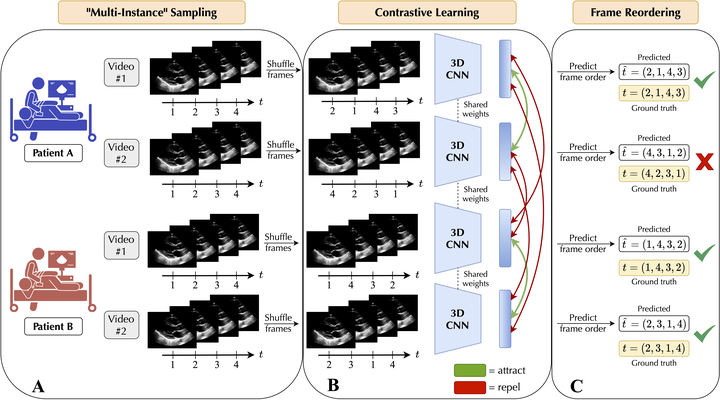
Methods: We developed a self-supervised contrastive learning approach, EchoCLR, for echocardiogram videos with the goal of learning strong representations for efficient fine-tuning on downstream cardiac disease diagnosis. EchoCLR pretraining involves (i) contrastive learning, where the model is trained to identify distinct videos of the same patient, and (ii) frame reordering, where the model is trained to predict the correct of video frames after being randomly shuffled.
Results: When fine-tuned on small portions of labeled data, EchoCLR pretraining significantly improves classification performance for left ventricular hypertrophy (LVH) and aortic stenosis (AS) over other transfer learning and SSL approaches across internal and external test sets. When fine-tuning on 10% of available training data (519 studies), an EchoCLR-pretrained model achieves 0.72 AUROC (95% CI: [0.69, 0.75]) on LVH classification, compared to 0.61 AUROC (95% CI: [0.57, 0.64]) with a standard transfer learning approach. Similarly, using 1% of available training data (53 studies), EchoCLR pretraining achieves 0.82 AUROC (95% CI: [0.79, 0.84]) on severe AS classification, compared to 0.61 AUROC (95% CI: [0.58, 0.65]) with transfer learning.