High sensitivity methods for automated rib fracture detection in pediatric radiographs
Abstract
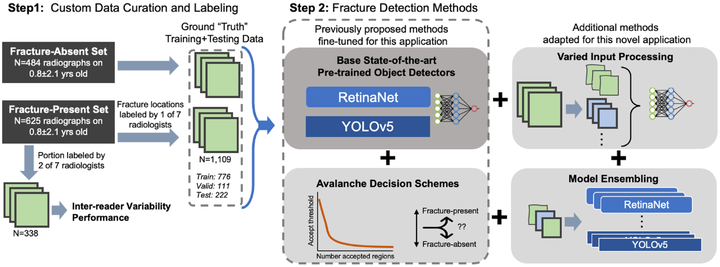
Rib fractures are highly predictive of non-accidental trauma in children under 3 years old. Rib fracture detection in pediatric radiographs is challenging because fractures can be obliquely oriented to the imaging detector, obfuscated by other structures, incomplete, and non-displaced. Prior studies have shown up to two-thirds of rib fractures may be missed during initial interpretation. In this paper, we implemented methods for improving the sensitivity (i.e. recall) performance for detecting and localizing rib fractures in pediatric chest radiographs to help augment performance of radiology interpretation. These methods adapted two convolutional neural network (CNN) architectures, RetinaNet and YOLOv5, and our previously proposed decision scheme, “avalanche decision”, that dynamically reduces the acceptance threshold for proposed regions in each image. Additionally, we present contributions of using multiple image pre-processing and model ensembling techniques. Using a custom dataset of 1109 pediatric chest radiographs manually labeled by seven pediatric radiologists, we performed 10-fold cross-validation and reported detection performance using several metrics, including F2 score which summarizes precision and recall for high-sensitivity tasks. Our best performing model used three ensembled YOLOv5 models with varied input processing and an avalanche decision scheme, achieving an F2 score of 0.725 ± 0.012. Expert inter-reader performance yielded an F2 score of 0.732. Results demonstrate that our combination of sensitivity-driving methods provides object detector performance approaching the capabilities of expert human readers, suggesting that these methods may provide a viable approach to identify all rib fractures.